海量数据处理
1.1.1 ba基于海量数据的本地化高速检索与统计计算技术
1.1.1.1 必要性
为了实现能够支撑全球互联网和年度时间尺度的数据检索、统计,需要从工程上实现十亿量级数据的快速检索技术,保障数据的高速可读性,重点解决数据库的扩展性、数据写入性能、数据查询性能、关联数据搜索性能的问题。
因为离线数据量庞大,每日更新数据量可达到百万级别,数据字段内容达数百个,因此数据在查询检索、统计上的压力比较大,其主要来自于查询检索过程中I/O性能上的约束,通过传统进行数据遍历式的检索方式,已经无法满足快速检索和统计的需求。
1.1.1.2 解决途径
解决海量数据本地化高速检索与统计计算遇到问题,需要从底层数据架构、数据存储方式、数据缓存机制、内容索引和性能调优几个方面综合分析解决。
- 在底层采用大数据平台分布式架构,CassandraNoSQL数据库、ElasticSearch存储引擎,数据存储按照点分割存储到不同的机器上面,解决扩展性问题;
- 由于采用NoSQL存储写性能是优于读性能的,因此解决数据写入性能问题重点需解决正常数据写入所伴随的大量读请求。通过引入了Redis缓存,缓存顶点的ID信息,较少读请求时间,从而优化数据写人的性能;
- 提升数据查询性能方面,依托底层采用的NoSQL数据存储,将正常请求自动分发到对应节点执行,并根据需求扩容数据节点;采用基于Spark的查询引擎分布式执行需要多步遍历的查询。
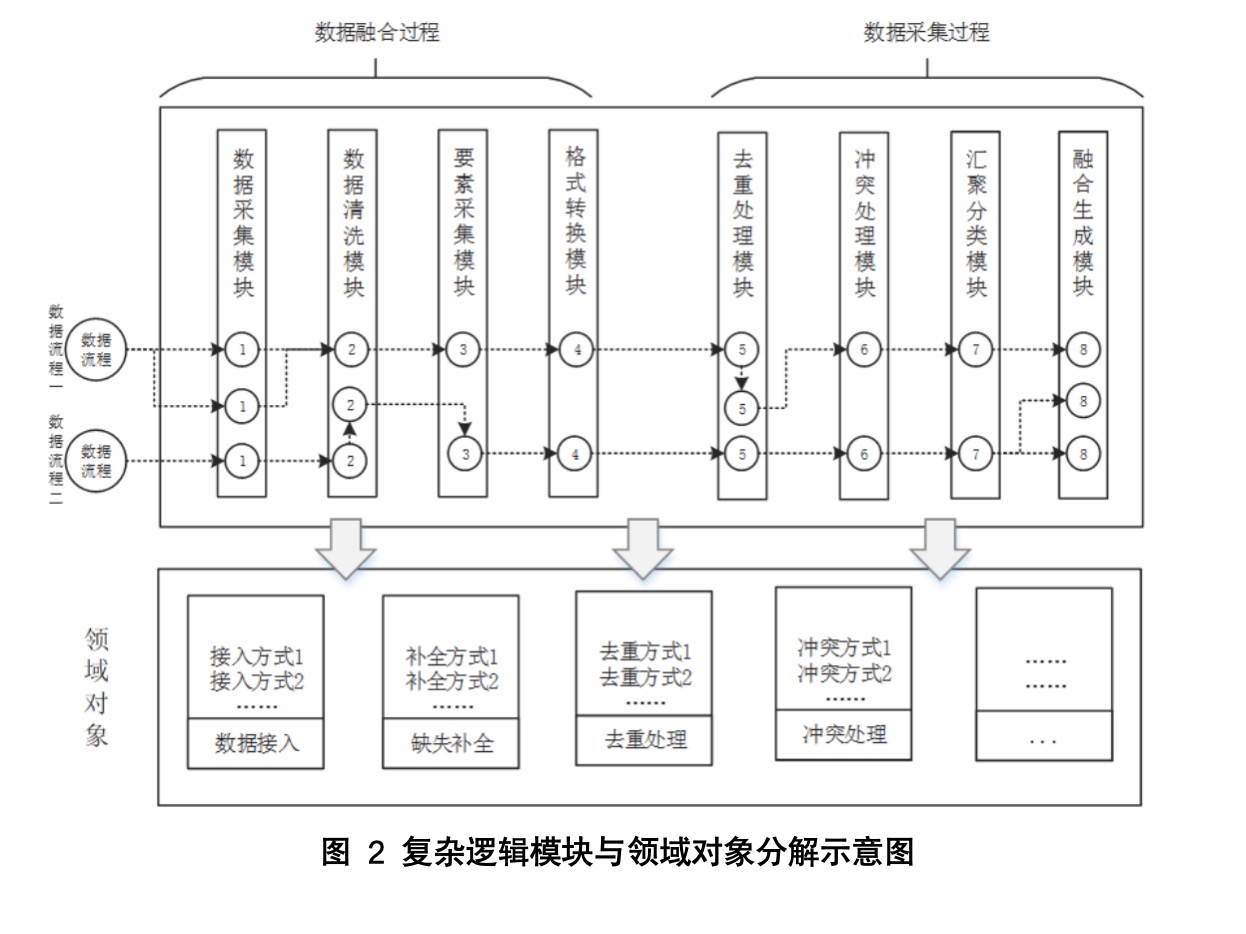
- 在提升超大规模数据搜索方面,将采用分布式计算的方式进行所示,如图3-5所示,先通过索引找到与查询检索相信息ID,通过ID检索到对应的数据内容,再对该顶点的边集合进行分布式搜索,最后实现归并计算。
1.1.2 海量安全数据ETL性能优化技术
0x01 引言
ETL概念
ETL的含义是将业务系统的数据经过抽取(Extract)、清洗转换(Transform)之后加载(Load)到数据仓库的过程,目的是为了将企业中零散的、不标准的、不统一的数据整合起来,并输出标准和统一的数据源,为企业决策提供数据依据。实现ETL的方法主要有两种,一种是通过编程语言去实现,但是门槛较高,一般人不易掌握。另一种是借助ETL工具去实现,这种方式比较灵活,而且图形化的界面操作起来比较简单,现在大部分有数据仓库需求的企业都是采用这种方式。
随着信息化和网络安全需求的日益增长,海量安全数据的处理成为了一个重要议题。ETL(Extract, Transform, Load)作为数据仓库建设中的重要环节,对于海量安全数据的处理尤为关键。本文将针对海量安全数据的ETL性能优化技术进行总结。
网络空间的海量安全大数据需要经过数据抽取、转换、清洗、加载等过程后,最终装载到目标处理平台上。平台数据ETL过程主要包括两类机制。一是数据全量加载更新机制,它是对海量安全数据在进行初始化时完成一次性加载更新;二是数据增量加载更新机制,它是根据数据内容指定字段中的时间戳或是属性变化情况,对全量数据库进行增量更新。在这些过程中,目标处理平台需要确保数据的正确性、完整性、一致性、完备性、有效性、时效性、可获取性等成为主要的关键技术点。
随着信息化和网络安全需求的日益增长,海量安全数据的处理成为了一个重要议题。ETL(Extract, Transform, Load)作为数据仓库建设中的重要环节,对于海量安全数据的处理尤为关键。本文将针对海量安全数据的ETL性能优化技术进行总结。
网络空间的海量安全大数据需要经过数据抽取、转换、清洗、加载等过程后,最终装载到目标处理平台上。平台数据ETL过程主要包括两类机制。一是数据全量加载更新机制,它是对海量安全数据在进行初始化时完成一次性加载更新;二是数据增量加载更新机制,它是根据数据内容指定字段中的时间戳或是属性变化情况,对全量数据库进行增量更新。在这些过程中,目标处理平台需要确保数据的正确性、完整性、一致性、完备性、有效性、时效性、可获取性等成为主要的关键技术点。
0x02 ETL性能优化的重要性
在海量安全数据的处理中,ETL的性能直接关系到数据仓库的建设效率以及后续数据分析的准确性与时效性。性能不佳的ETL过程可能导致数据处理效率低下、数据延迟等问题,进而影响整个安全数据分析和决策过程。
0x03 ETL性能优化技术
- 硬件资源优化 o增加内存、CPU等硬件资源,提高数据处理能力。 o使用高性能存储系统,如SSD硬盘,减少I/O等待时间。
- 并行处理 o利用多线程、分布式计算等技术实现数据并行处理,提高处理速度。 o通过任务拆分和负载均衡,确保各个处理节点能够高效协作。
- 数据缓存 o在ETL过程中使用数据缓存技术,减少重复读取数据源的开销。 o利用内存数据库或缓存中间件等技术,提高数据访问速度。
- 索引与分区 o在数据转换和加载过程中,合理使用索引和分区技术,提高数据检索和加载效率。 o根据数据特点选择合适的索引策略和分区策略,优化数据访问性能。
- 代码优化 o优化ETL脚本和代码,减少不必要的计算和逻辑判断。 o使用高效的算法和数据结构,提高数据处理效率。
- 日志与监控
o实时监控ETL过程,及时发现和处理性能瓶颈。
o通过日志分析,了解ETL过程中各个环节的性能表现,为优化提供依据。 0x04 解决途径
因此,本项目研究的目标处理平台需要是面向主题的、集成的、稳定的,能够高效处理不同时间的数据集合:
(1)目标处理平台图数据库的点边数据能够按照主体组织;
(2)能够稳定从多个数据源将数据集合到平台中,并集成为一个整体;
(3)由于海量数据库存储,对数据层的操作,将设计采用基于日志的事物一致性方案,解决更新的一致性问题;
(4)对于海量数据的导入,为了避免查询顶点ID的性能问题,采用了缓存技术,将需要查询的ID缓存到高速缓存存储系统,保证全量数据导入的性能。
0x05 总结与展望
海量安全数据的ETL性能优化是一个持续的过程,需要不断根据实际需求和技术发展进行改进和调整。未来,随着云计算、大数据等技术的不断发展,海量安全数据的ETL性能优化将面临更多的挑战和机遇。通过不断研究和实践新的优化技术,可以进一步提高海量安全数据的处理效率和准确性,为网络安全提供更加坚实的数据支持。
1.1.3 海量多源异构数据采集处理技术
1.1.3.1 必要性
在进行数据采集的过程中,对原始素材进行数据处理,抽取出高价值、标准化、高可用的数据是重要的先决技术条件。如表所示,原始素材来源渠道广泛、类型多样化、数据承载形式不一、具体格式标准,这给数据标准化处理过程带来了极大的挑战,该数据处理过程所需要的技术是系统数据采集服务的关键技术之一。 表 1数据对象内容表 素材来源渠道 素材类型 数据承载形式 数据格式类型 防火墙模块 网络通信日志 网络日志流数据 自有A格式 终端安全防护模块 终端行为日志 文本txt类型 自有B格式 系统数据接入 接口数据文件 Json数据格式 自有C格式 系统数据导出 导入导出文件 Csv、Excel文件 自有D格式 工控扫描数据 指纹匹配结果 Sql文件、json文件 自有E格式 蜜罐诱捕数据 攻击行为数据 json文件 自有F格式
1.1.3.2 解决途径
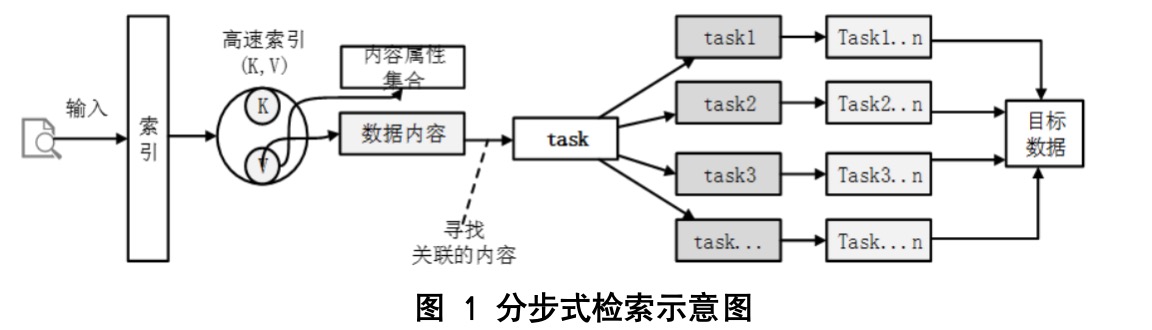
海量多源异构数据处理技术基于对多源异构数据(终端安全、搜索引擎等各类数据)处理经验和现有技术基础,结合实际业务流程,对该项关键技术按照数据处理流程模块化、处理方式领域化和数据格式定制化进行分解,根据原始素材和实现数据目标的属性内容进行实现,通过对各来源的数据设置数据处理过程和预置数据内容处理规则,使用OPL(objects-properties-links)数据提取方式,将提取的数据与系统标准数据进行字段关联映射,达到提取目标数据的效果。
海量多源异构数据处理技术在数据处理过程时将预处理的内容进行过程分级选择和处理方式选择。分级选择是针对数据采集和数据融合的具体过程,如对某个数据段选数据采集采集方式、清洗方式、要素内容、转换格式,选择后可具体到每个步骤的处理内容,如清洗方式可选择数据缺失补全、数据模糊计算、逻辑错误处理等。在预置数据内容处理规则时,对目标数据片段内容进行系统字段映射,在数据处理流程的过程中进行对象生成、属性补全和关系确定。最终对不同来源数据、不同格式化的数据进行过程规则和数据规则来实现该项关键技术。
目前数据处理流程模块化和数据处理方式领域化技术已有相关模型,对于特定处理流程模块需要从业务的角度理解研发,并结合定制化的数据模型与领域对象结合进行适配。